This post will only use one-based indexing since that’s what Fenwick trees traditionally use, although they can also be modified to use zero-based indexing.
So imagine you have an array $A$ of size $N$, and you’d like to support two operations. The first one, called $Update(i, v)$, is trivial: Given an index $i$, add $v$ to $A_i$. Easy peasy!
A[i] += v;
Cool. For the second operation, $RangeQuery(i, j)$, you’re given $i$ and $j$, and you’d like to find the sum of the elements of $A$ between indices $[i, j]$ inclusive. Also super easy, right?
int ans = 0;
for (; i <= j; i++)
ans += A[i];
Problem is, that’s really inefficient if $A$ is huge! Due to that loop, $RangeQuery$ takes $O(N)$ time. However, $Update$ is as fast as it could possibly be and only takes $O(1)$ time. So, can we do better for $RangeQuery$?
Prefix sums
Summing from $i$ to $j$ is really slow. What if we had some sums already computed? Specifically, if we knew the sum from $[1, j]$, and subtracted the sum from $[1, i - 1]$, we’d end up with the sum from $[i, j]$. This only takes $O(1)$ time!
To make this more precise, let $P_i = \sum_{k = 1}^i A_k$. This is called the prefix sum of array $A$. We can compute $P$ in $O(N)$ time by observing that $P_i$ is the sum of the current element, $A_i$ and everything before it, $P_{i - 1}$.
for (int i = 1; i <= N; i++)
P[i] = A[i] + P[i - 1];
As noted before, $RangeQuery(i, j) = P_j - P_{i-1}$ which is super fast.
return P[j] - P[i - 1];
However, for $Update(i, v)$, we’ll mess up the prefix sums for all indices past $i$! Thus, we have to loop over all of them and add $v$ to each.
for (; i <= N; i++)
P[i] += v;
Fenwick trees
So here’s what we have so far. With a plain array, we have $O(1)$ for $Update$ and $O(N)$ for $Query$. With prefix sums, we get $O(N)$ for $Update$ and $O(1)$ for $Query$. Ugh. But is there a sweet spot in the middle where both are fast?
There’s a technique called square root decomposition that can achieve $O(\sqrt{N})$ for both, but I won’t go into it here. Instead, let’s jump straight to the good stuff.
Actually, not so fast! You should learn about segment trees first. They’re even better and can handle both operations with ease in only $O(\log N)$. They share some similar ideas as Fenwick trees, but are a lot simpler to learn and reason with. There are tons of great resources online that explain segment trees, so I won’t do that here.
Alright, so imagine you had a segment tree but it was really shriveled up and dying. Wait no, that’s not a very helpful metaphor. Let me explain it like this. A segment tree can represent any $[i, j]$ interval as a union of its nodes. Fenwick trees can’t do that. They have fewer nodes, only $N$, and can only represent intervals $[1, i]$ as a union of their nodes! Thus, they don’t directly handle $RangeQuery(i, j)$ and instead support the operation $Query(i) = RangeQuery(1, i)$.
But don’t get me wrong, Fenwick trees are way cooler! They use one quarter the memory of segment trees, are much faster since they use bit hacks and iteration instead of recursion, can be implemented super concisely. (Yeah I know there’s also a way to implement segment trees with iteration, but no one does that.)
Here are two diagrams, one that I drew and another made by my friend Isaac respectively. Thanks Isaac! (He also convinced me to write this post.) Formally, node $i$ covers an interval ending at $i$ and length equal to the largest power of 2 that divides $i$. But just admire the visual elegance of it all.
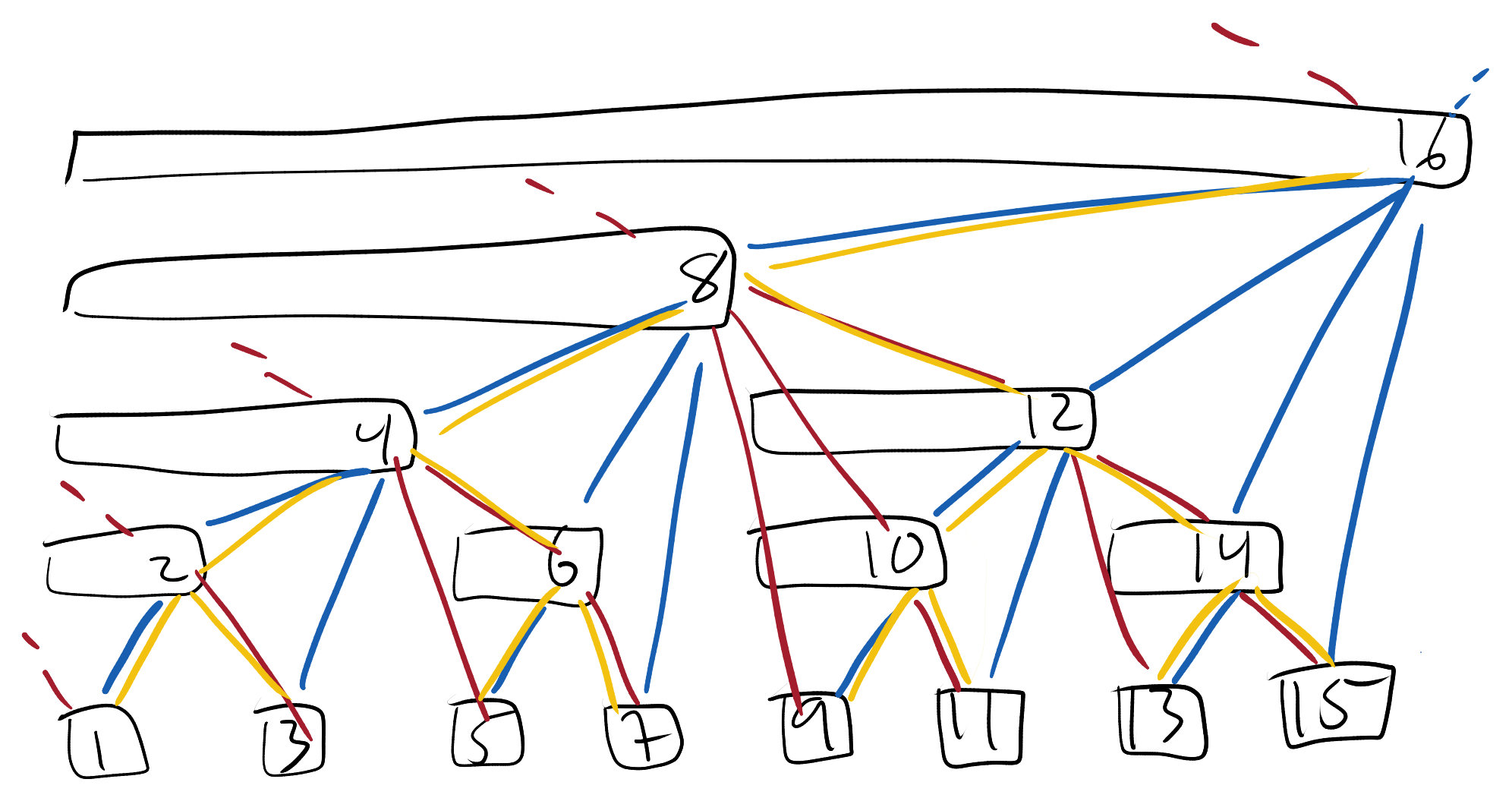
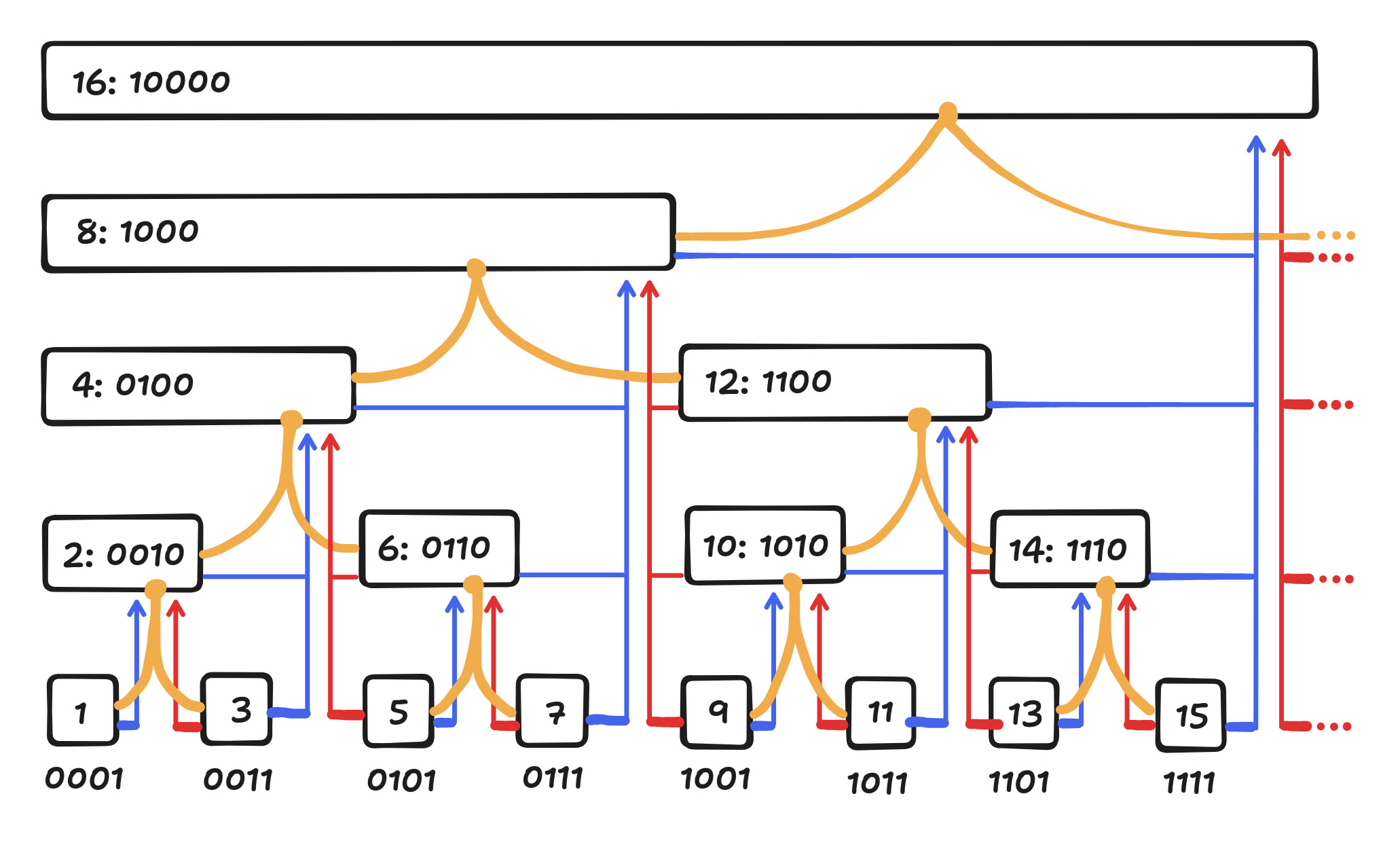
Let’s say you call $Query(11)$. The interval $[1, 11]$ is covered by nodes 8, 10, and 11. This corresponds to starting at 11, walking one space to the left, and going up. Then repeat this process until you reach the left side, which is 0. Try out some examples using the diagrams above! Formally, each step, marked by the red edges, involves turning off the rightmost 1 in the binary representation of your current node, which can be done with a crazy bit hack. The red edges correspond to a binomial tree (not to be confused with binomial heaps). Here’s the code for $Query(i)$, where $F_i$ is the value stored in node $i$:
int ans = 0;
for (; i; i -= i & -i)
ans += F[i];
That’s it! Easy as that. What about $Update(i, v)$? For instance, let’s do $Update(5, v)$. We need to update all the nodes that cover index 5, which corresponds to starting at 5, walking one space to the right, and going up. The repeat this process until you reach the top. Formally, at each step, marked by the blue edges, we add 1 to the rightmost 1 in the binary representation of your current node and propagate the carry, which can also be done with a crazy bit hack. The blue edges correspond to a different binomial tree, symmetric to the red tree. Here’s the code for $Update(i, v)$:
for (; i <= N; i += i & -i)
F[i] += v;
Now to handle $RangeQuery(i, j)$, we’ll use the same idea from prefix sums! It’s simply $Query(j) - Query(i - 1)$.
And there you go! That’s how you can do both $Update$ and $RangeQuery$ in $O(\log N)$ time, since both trees have depth $\log N + 1$. If that didn’t quite make sense yet, work out a bunch of examples. Or read someone else’s explanation of Fenwick trees (also known as binary indexed trees) since I probably didn’t do a great job here. Note that “Fenwick tree” is a misnomer, since it’s actually an array with two implicit binomial trees on it. Buy one get one free, I guess.
Now time for the fun and obscure stuff!
Efficiently building it
So let’s say your array $A$ is all zeros. Then obviously the Fenwick tree for this array is also all zeros, since each node covers an interval containing only zeros. But what if $A$ already has some stuff in it? And what if you want to save memory by converting an array in-place to a Fenwick tree?
The naive method would be to start with all zeros and call $Update(i, A_i)$ $N$ times for each $i$. This takes $O(N \log N)$ time.
But let’s do even better. We’ll use the same idea as how we efficiently built the prefix sum array. Note that each node $i$ is the sum of $A_i$ and its child nodes. So, we can start from node 1 and propagate these sums upwards!
for (int i = 1; i <= N; i++) {
int j = i + (i & -i);
if (j <= N)
F[j] += F[i];
}
Faster range queries
You may have noticed that some queries have some redundancy, for instance
\begin{align*} RangeQuery(11, 15) &= Query(15) - Query(10) \\ &= (F_{15} + F_{14} + F_{12} + F_8) - (F_{10} + F_8) \\ &= F_{15} + F_{14} + F_{12} - F_{10} \end{align*}
We can make $RangeQuery(i, j)$ slightly faster by stopping $Query(j)$ once we reach a node less than $i$. Here’s the code:
int ans = 0;
for (; j >= i; j -= j & -j)
ans += F[j];
for (i--; i > j; i -= i & -i)
ans -= F[i];
But how much faster is it? For simplicity, assume $N = 2^B$. $Query(j)$ will stop once it reaches the lowest common ancestor (LCA) of both $i - 1$ and $j$ in the red tree, which is the value of the matching prefix of $i - 1$ and $j$ in binary. For instance, 13 and 15 have the LCA 12 because 13 is 1101 and 15 is 1111, so their matching prefix is 1100 which is 12. To compute the speedup of stopping at the LCA, we can brute force over all possible $i - 1$ and $j$ and how many ones are in their matching prefix, which we can skip, to determine the speedup.
B = 12 # Bits
fasttime = 0
speedup = 0
for x in range(2**B):
for y in range(x + 1, 2**B):
xs = bin(x)[2:].zfill(B)
ys = bin(y)[2:].zfill(B)
i = 0 # Matching prefix length
j = 0 # Number of 1s in matching prefix
while i < B and xs[i] == ys[i]:
if xs[i] == '1':
j += 1
i += 1
k = xs[i:].count('1') # Number of 1s after prefix in smaller num
l = ys[i:].count('1') # Number of 1s after prefix in larger num
fasttime += k + l + 2
speedup += 2 * j
print(speedup / fasttime, fasttime / 2**(2 * B), speedup / 2**(2 * B))
Python is slow, and brute force is also slow. To compute the speedup even faster, we can iterate over all i,j,k,l combinations and calculate their probabilities.
from math import comb
B = 17 # Bits
fasttime = 0
speedup = 0
for i in range(B): # Matching prefix length
for j in range(i + 1): # Number of 1s in matching prefix
for k in range(B - i): # Number of 1s after prefix in smaller num, must have 0 at mismatch
for l in range(1, B - i + 1): # Number of 1s after prefix in larger num, must have 1 at mismatch
prob = (comb(i, j) / 2**i) * (comb(B - i - 1, k) / 2**(B - i - 1)) \
* (comb(B - i - 1, l - 1) / 2**(B - i - 1)) * 0.5**i * 0.25
fasttime += prob * (k + l + 2)
speedup += prob * 2 * j
print(speedup / fasttime, fasttime, speedup)
I verified these two programs match for small $B$, so I hope it’s correct. For $B = 17$, it outputs 0.055547949705314514 8.999996185302734 0.49993133544921875, which means queries using this optimization take around 9 loop iterations and the optimization shaves off around 0.5 of an iteration. It’s a 5% speedup, roughly, which isn’t too bad!
I also timed my implementations of $RangeQuery$ written in C and the speedup is indeed around 5%! That said, there’s a lot of noise and I didn’t do statistics so maybe I’m just lucky.
Prefix search
You might be wondering about that yellow tree in the diagrams above. That’s actually the original reason I wanted to write this post but then mission creep happened and here we are.
I have a ridiculously overengineered flash cards app. For the app, I needed an efficient way to sample from a weighted distribution and update the weights. My solution, of course, is a Fenwick tree, although an array would honestly work pretty well given that no one actually has flash card decks with millions of cards.
Anyways, I’m just using the same $Update$ operation as explained above. But for sampling from the distribution, my method is to pick a random number $s$ between 0 and the sum of all the weights, and find the index whose prefix sum less than or equal to $s$. This is sort of the inverse operation as $Query$.
But, as expected, Fenwick trees are awesome and can do this too! Let’s call the operation $Search(s)$. Take a look at the diagram again. The yellow tree is a binary tree, and we can start from the top node and walk down. At each node, check its left child’s sum. If it’s less than $s$, than descend into the left child. Otherwise, we’ve covered that sum with the left child, so subtract it from $s$, and descend into the right child. Note that this requires all array elements to be nonnegative.
As always, the code is short and sweet:
int ans = 0;
// i is the largest power of 2 less than or equal to N
for (int i = 1 << (8 * sizeof(int) - __builtin_clz(N) - 1); i; i >>= 1)
if (ans + i <= N && F[ans + i] <= s)
s -= F[ans += i];
I learned about this from an arXiv paper so it’s a pretty obscure Fenwick tree feature. It’s also a weird operation in that it walks down a tree, and uses a symmetric binary tree instead of a binomial tree. So it’s actually buy one get two free! It’s one array. Three trees.
Range updates
I think we’ve beaten $Update$ and $RangeQuery$ to death at this point, so what if it’s the other way around? $RangeUpdate(i, j, v)$ for adding $v$ to the entire interval $[i, j]$, and $PointQuery(i)$ for returning the value $A_i$?
It’s actually pretty easy to solve this, but I’m going to introduce some weird notation that I made up that will be helpful later. We’ll call the prefix sum of $A$ its discrete integral and notate it as $\int A$, so $\int A_i = \sum_{k = 1}^i A_i$. We’ll also define the discrete derivative of $A$ to be $DA_i = A_i - A_{i-1}$. They have nothing to do with actual calculus. I just came up with cute names for them.
By plugging in the definitions, we can show
\begin{align*} D\int A_i &= A_i \\ \int DA_i &= A_i. \end{align*}
A Fenwick tree constructed on array $A$ enables us to read from the value of $\int A_i$ and write to the value of $A_i$.
The solution to our $RangeUpdate, PointQuery$ task is to construct a Fenwick tree on $DA$ instead! This lets us read from $D\int A_i = A_i$ and write to $DA_i$. Note that $RangeUpdate(i, j, v)$ only changes $DA_i$ and $DA_{j+1}$ because that’s where the “bumps” are. Everything in the middle stays the same. Thus, problem solved!
Here’s $RangeUpdate(i, j, v)$, which calls the $Update(i, v)$ function for a standard point-update, range-query Fenwick tree $F$. The other operation $PointQuery(i)$ simply calls $Query(i)$ for $F$.
update(N + 1, F, i, v);
update(N + 1, F, j + 1, -v);
One implementation detail to be aware of is that your Fenwick tree on $DA$ should have length one larger than $A$ so that the $j + 1$ is still a valid index.
Range updates and range queries!
Hopefully by now you’re convinced that Fenwick trees are awesome. They can do point updates and range queries. They can do range updates and point queries. But what about range updates and range queries?
Segment trees can famously do that using lazy propagation, but guess what? Fenwick trees have this superpower too.
So let’s take our Fenwick tree from the previous section, which reads from $A_i$ and writes to $D A_i$. Great, that can handle range updates. But how can we read from $\int A_i$ for range queries? We need a new Fenwick tree, but the only way to handle range updates efficiently is with two writes to $D A_i$… or what about $i \cdot D A_i$? We can also write to that efficiently by replacing any $update(i, v)$ with $update(i, i \cdot v)$.
An intuitive reason for why we should do that is because of (sketchy) dimensional analysis. Imagine that $A$ was not an array but a function where $A_i$ has units $m$ and the indices $i$ have units $s$. Then in some sense, $\int A_i$ has units $m\cdot s$ and $D A_i$ has units $m/s$. Our Fenwick tree from the previous section reads from units $m$ and writes to units $m/s$, but we’d really like it to read from units $m\cdot s$ instead. By multiplying by $i$ which has units $s$, we can “lift up” our new Fenwick tree to the right units.
Alright, so our new Fenwick tree writes to $i \cdot D A_i$, so by definition it reads from $\int(i \cdot D A_i)$. So now what? Well, let’s plug in the definition of the discrete derivative since it’s the only easy thing we can do now.
\[\int(i \cdot D A_i) = \int(i \cdot A_i - i \cdot A_{i-1})\]
That expression inside the integral looks almost like $D(i \cdot A_i)$! We just need the $i \cdot A_{i-1}$ to be $(i - 1) \cdot A_{i-1}$ instead, so let’s split apart that term.
\begin{align*} \int(i \cdot D A_i) =& \int(i \cdot A_i - (i - 1) \cdot A_{i-1} - A_{i-1}) \\ =& \int(D(i \cdot A_i)- A_{i-1}) \\ =& \int D(i \cdot A_i) - \int A_{i-1} \\ =& i \cdot A_i - \int A_{i-1} \end{align*}
Whoa! There’s our answer, our beloved $\int A_i$, in a slightly mangled form! To extract the answer, we need to $-query(i + 1)$ instead of $query(i)$ and add the extra $(i + 1) \cdot A_{i+1}$. Luckily, our Fenwick tree from the previous section can already read from $A_{i}$ to help us find $(i + 1) \cdot A_{i+1}$, so we’ll need to maintain two Fenwick trees instead of one.
And finally, the code in all its glory:
void range_update(int N, int *F, int *G, int i, int j, int v) {
update(N, F, i, v);
update(N, F, j + 1, -v);
update(N, G, i, i * v);
update(N, G, j + 1, -(j + 1) * v);
}
int prefix_query(int N, int *F, int *G, int i) {
return -query(N, G, i + 1) + (i + 1) * query(N, F, i + 1);
}
int range_query(int N, int *F, int *G, int i, int j) {
return prefix_query(N, F, G, j) - prefix_query(N, F, G, i - 1);
}
I know the fake calculus looks pretty sketchy, but trust me, it’s all rigorous. And plus, the code works so how can it be wrong?
I don’t have great intuition for why this works though, since it seems to me to just be a mathematical miracle, but this article tries to explain this technique from a different (also confusing) perspective.
And a rabbit!
If you made it this far, congrats! Here’s Fenwick the rabbit and Segtree the squirrel!

Maybe they’re named that way since they live in trees. I remember when I first folded Segtree, I told me friends there was a squirrel in my room and they thought I had left the window open and got either extremely lucky or extremely unlucky.
More to explore
This is just scratching the surface of the awesome things you can do with Fenwick trees. For instance, what if $RangeQuery$ should return an arbitrary function over the range $[i, j]$ rather than the sum? Segment trees can do that, but turns out (of course) so can Fenwick trees! Also, I didn’t delve into any performance or implementation considerations, while in reality Fenwick trees can sometimes interact badly with caches (although they make up for that by being cool and fast anyways). That same paper also explores some crazy compression stuff.
For runnable versions of the code in this post, check out the Fenwick tree library (and Rust version) that I wrote for my flash cards app.
And some day I’ll write a similar post about splay trees, which are even more awesome, trust me. I just can’t promise the implementations will be as short and slick though!