Yesterday my friend wrote a blog post about their backup strategy so I guess I’ll do the same.
November was a data loss bonanza for me, both due to Saddam Hussein’s LinkedIn and an SSD failure, so I recently took some time to actually do backups properly. There are a gazillion backup tools out there, and I’ve tried a good chunk of them: rsync, rclone, bup, restic, duplicity…
But… they’re all wrong. There’s only ONE TRUE WAY to do backups, and that’s Btrfs send and receive. (Or ZFS. But I’ll focus on Btrfs in this post since that’s what I’m familiar with.) It’s super fast, efficient, and puts all these other tools to shame. Why? Because the filesystem itself knows exactly what’s changed between snapshots. It doesn’t use those puny stat abstractions that userspace tools are limited to. If you’re backing up one million files, all those other tools need to scan through all one million files to check if they’ve changed!
Anyways, here’s send and receive work. The btrfs send command produces a diff of two subvolumes A and B. And then btrfs receive applies that diff to another copy of A on a different disk. If your other copy of A is on a completely different machine, you can pipe the diff over SSH to do remote backups. Yay, it’s the Unix philosophy! Since all the magic happens at the filesystem level, Btrfs doesn’t even need to uncompress any files during the process if you’re using Btrfs on-disk compression (if you use the flag --compressed-data). See? It’s such a clean and efficient design.
It’s sadly not all sunshine and sparkles. send inspects filesystem internals and needs to run as root or with elevated privileges. Also, both sides need to have Btrfs filesystems of this obviously won’t work. So yeah, sometimes you do have to use those other tools, but send and receive really shine when doing efficient full system backups.
Since there are lots of great guides online on how to use send and receive, I won’t explain it here. For automating the process, check out Snapper and Btrbk. Instead, I’ll try to explain at a high level how this crazy magical Btrfs feature works.
How Btrfs send works
My understanding of Btrfs is pretty limited, since it’s a very complicated filesystem, but here’s a quick overview. Btrfs uses COW B-trees without leaf node linkages, plus some other fancy stuff, as its generic data structure and stores everything in these trees.
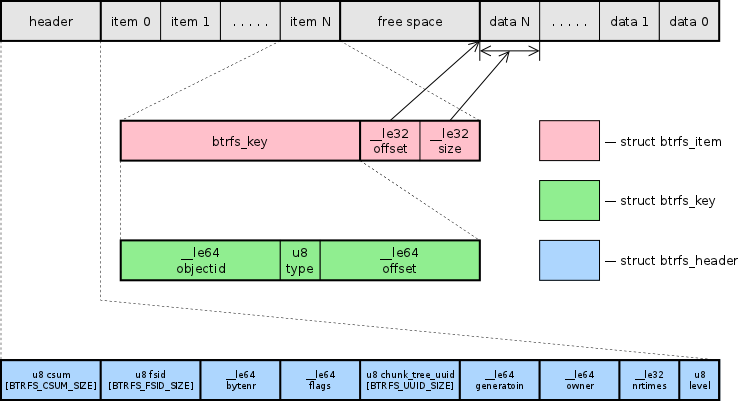
Each leaf node contains a header and a set of items. Each item contains a key and possibly data. The first 64 bits of each key contains the objectid of that item and must be unique, which is why a Btrfs filesystem can’t have more than 2^64 files. The keys are used to define the ordering for the tree. Upper nodes of the trees contain only key, block pointer pairs. Here’s the algorithm for send, copied from a research paper. Note that level 0 is the level with the leaf nodes.
Strategy: Go to the first items of both trees. Then do
If both trees are at level 0
Compare keys of current items
If left < right treat left item as new, advance left tree
and repeat
If left > right treat right item as deleted, advance right tree
and repeat
If left == right do deep compare of items, treat as changed if
needed, advance both trees and repeat
If both trees are at the same level but not at level 0
Compare keys of current nodes/leafs
If left < right advance left tree and repeat
If left > right advance right tree and repeat
If left == right compare blockptrs of the next nodes/leafs
If they match advance both trees but stay at the same level
and repeat
If they don't match advance both trees while allowing to go
deeper and repeat
If tree levels are different
Advance the tree that needs it and repeat
Advancing a tree means:
If we are at level 0, try to go to the next slot. If
that is not possible, go one level up and repeat. Stop when we found a level
where we could go to the next slot. We may at this point be on a node or a
leaf.
If we are not at level 0 and not on shared tree blocks, go one level deeper.
If we are not at level 0 and on shared tree blocks, go one slot to the right
if possible or go up and right.
I wasn’t able to find much else about the internals of Btrfs send apart from that paper and the original patchset (click the RFC PATCH links at the bottom to see the code, in particular part 5 which contains btrfs_compare_trees), but here are some resources about Btrfs internals in general:
How I use it
- The server for this website is hosted on XVM which has RAID, but also backed up daily to my laptop
sendandreceive. - I’m one of the maintainers of the MIT Mastodon server, which uses Btrfs RAID1 and the whole filesystem is also backed up daily to a third disk using
sendandreceive. (Note: Put large cache directories on separate subvolumes so they get omitted from backups.)
However, for my personal files, I’d like to sync them between my laptop and phone, which doesn’t use Btrfs. Thus, I’m using Syncthing instead which works fantastically because I only have a few thousand personal files, not a few million. I have a third device for Syncthing and also back up everything encrypted to the cloud using Déjà Dup (an amazing app that requires 0 IQ to use). The nice thing about cloud storage is that it’s storage without the pain of managing a server, and it’s encrypted anyways.